Download Fortinet NSE 8 - Written Exam.NSE8_812.CertDumps.2023-07-05.20q.vcex
| Vendor: | Fortinet |
| Exam Code: | NSE8_812 |
| Exam Name: | Fortinet NSE 8 - Written Exam |
| Date: | Jul 05, 2023 |
| File Size: | 13 MB |
| Downloads: | 1 |
How to open VCEX files?
Files with VCEX extension can be opened by ProfExam Simulator.
Discount: 20%





Demo Questions
Question 1
Refer to the exhibits.
Exhibit A

Exhibit B
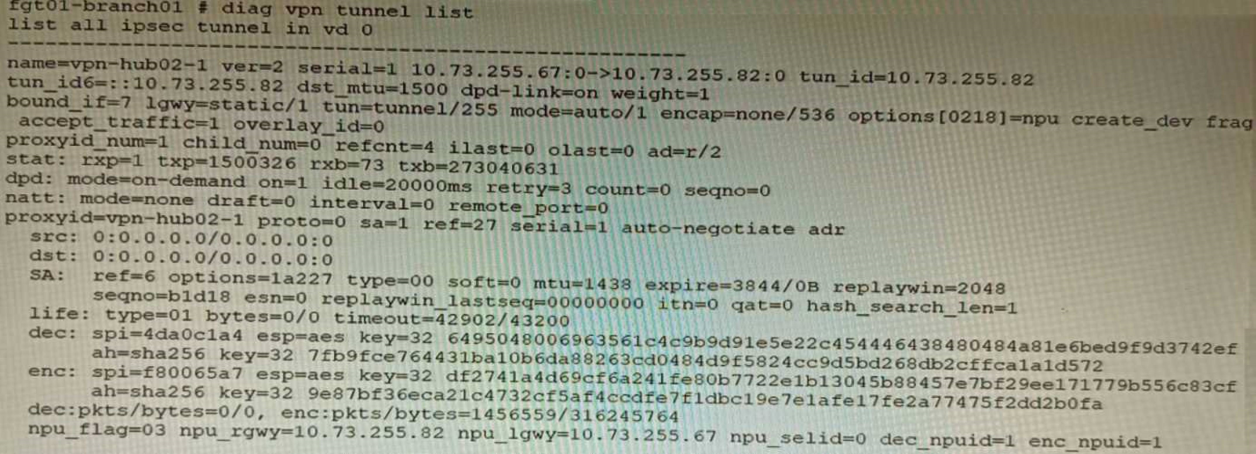
Exhibit C

A customer is trying to set up a VPN with a FortiGate, but they do not have a backup of the configuration. Output during a troubleshooting session is shown in the exhibits A and B and a baseline VPN configuration is shown in Exhibit C
Referring to the exhibits, which configuration will restore VPN connectivity?
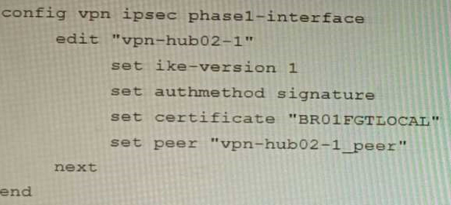

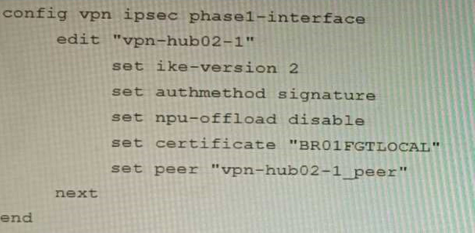

Correct answer: B
Explanation:
The VPN configuration shown in Exhibit C is a baseline VPN configuration that uses IKEv2 with preshared keys and AES256 encryption for both IKE and ESP phases. However, this configuration does not match the output shown in Exhibit A and B, which indicate that IKEv1 is used with RSA signatures and AES128 encryption for both IKE and ESP phases. Therefore, to restore VPN connectivity, the configuration needs to be modified to match these parameters. Option B shows the correct configuration that matches these parameters. Option A is incorrect because it still uses IKEv2 instead of IKEv1. Option C is incorrect because it still uses pre-shared keys instead of RSA signatures. Option D is incorrect because it still uses AES256 encryption instead of AES128 encryption. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/cookbook/19662/ipsec-vpn-with-forticlient The VPN configuration shown in Exhibit C is a baseline VPN configuration that uses IKEv2 with preshared keys and AES256 encryption for both IKE and ESP phases. However, this configuration does not match the output shown in Exhibit A and B, which indicate that IKEv1 is used with RSA signatures and AES128 encryption for both IKE and ESP phases. Therefore, to restore VPN connectivity, the configuration needs to be modified to match these parameters. Option B shows the correct configuration that matches these parameters. Option A is incorrect because it still uses IKEv2 instead of IKEv1. Option C is incorrect because it still uses pre-shared keys instead of RSA signatures. Option D is incorrect because it still uses AES256 encryption instead of AES128 encryption.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/cookbook/19662/ipsec-vpn-with-forticlient
Question 2
An HA topology is using the following configuration:
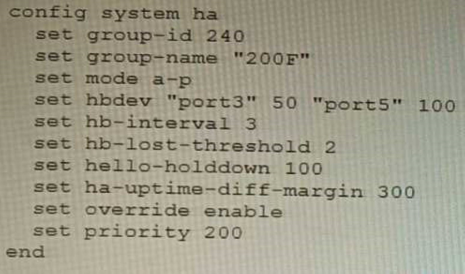
Based on this configuration, how long will it take for a failover to be detected by the secondary cluster member?
- 600ms
- 200ms
- 300ms
- 100ms
Correct answer: C
Explanation:
The HA topology shown in the exhibit is using link monitoring with two heartbeat interfaces (port3 and port5) and a heartbeat interval of 100ms. Link monitoring is a feature that allows HA failover to occur when one or more monitored interfaces fail or become disconnected. The heartbeat interval is the time between each heartbeat packet sent by an HA cluster unit to other cluster units through heartbeat interfaces. The failover time is determined by multiplying the heartbeat interval by three (the default deadtime value). Therefore, in this case, the failover time is 100ms x 3 = 300ms. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/administration-guide/647723/linkmonitoring-and-ha-failover-time The HA topology shown in the exhibit is using link monitoring with two heartbeat interfaces (port3 and port5) and a heartbeat interval of 100ms. Link monitoring is a feature that allows HA failover to occur when one or more monitored interfaces fail or become disconnected. The heartbeat interval is the time between each heartbeat packet sent by an HA cluster unit to other cluster units through heartbeat interfaces. The failover time is determined by multiplying the heartbeat interval by three (the default deadtime value). Therefore, in this case, the failover time is 100ms x 3 = 300ms.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/administration-guide/647723/linkmonitoring-and-ha-failover-time
Question 3
Refer to the exhibit.

You have deployed a security fabric with three FortiGate devices as shown in the exhibit. FGT_2 has the following configuration:
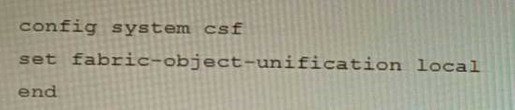
FGT_1 and FGT_3 are configured with the default setting. Which statement is true for the synchronization of fabric-objects?
- Objects from the FortiGate FGT_2 will be synchronized to the upstream FortiGate.
- Objects from the root FortiGate will only be synchronized to FGT__2.
- Objects from the root FortiGate will not be synchronized to any downstream FortiGate.
- Objects from the root FortiGate will only be synchronized to FGT_3.
Correct answer: A
Explanation:
The security fabric shown in the exhibit consists of three FortiGate devices connected in a hierarchical topology, where FGT_1 is the root device, FGT_2 is a downstream device, and FGT_3 is a downstream device of FGT_2. FGT_2 has a configuration setting that enables fabric-object synchronization for all objects except firewall policies and firewall policy packages (set sync-fabricobjects enable). Fabric-object synchronization is a feature that allows downstream devices to synchronize their objects (such as addresses, services, schedules, etc.) with their upstream devices in a security fabric. This simplifies object management and ensures consistency across devices. Therefore, in this case, objects from FGT_2 will be synchronized to FGT_1 (the upstream device), but not to FGT_3 (the downstream device). Objects from FGT_1 will not be synchronized to any downstream device because the default setting for fabric-object synchronization is disabled. Objects from FGT_3 will not be synchronized to any device because it does not have fabric-object synchronization enabled. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/administration-guide/19662/fabric-objectsynchronization The security fabric shown in the exhibit consists of three FortiGate devices connected in a hierarchical topology, where FGT_1 is the root device, FGT_2 is a downstream device, and FGT_3 is a downstream device of FGT_2. FGT_2 has a configuration setting that enables fabric-object synchronization for all objects except firewall policies and firewall policy packages (set sync-fabricobjects enable). Fabric-object synchronization is a feature that allows downstream devices to synchronize their objects (such as addresses, services, schedules, etc.) with their upstream devices in a security fabric. This simplifies object management and ensures consistency across devices.
Therefore, in this case, objects from FGT_2 will be synchronized to FGT_1 (the upstream device), but not to FGT_3 (the downstream device). Objects from FGT_1 will not be synchronized to any downstream device because the default setting for fabric-object synchronization is disabled. Objects from FGT_3 will not be synchronized to any device because it does not have fabric-object synchronization enabled.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/administration-guide/19662/fabric-objectsynchronization
Question 4
QUESTION Refer to the exhibit.

You are operating an internal network with multiple OSPF routers on the same LAN segment. FGT_3 needs to be added to the OSPF network and has the configuration shown in the exhibit. FGT_3 is not establishing any OSPF connection.
What needs to be changed to the configuration to make sure FGT_3 will establish OSPF neighbors without affecting the DR/BDR election?

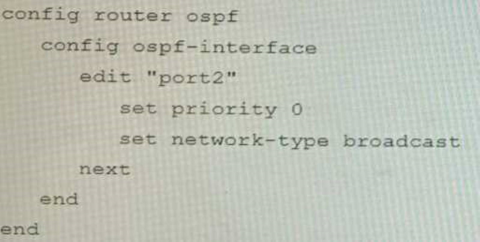
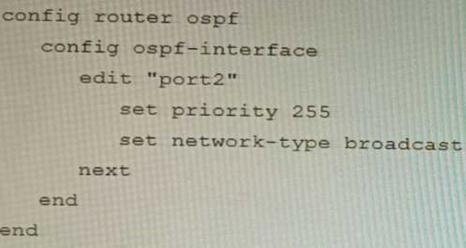
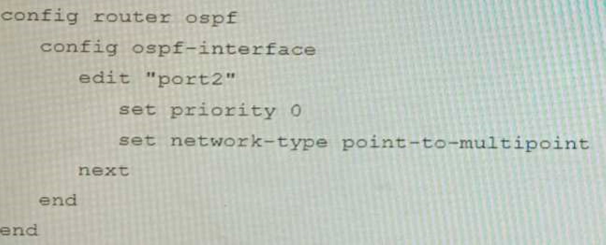
Correct answer: B
Explanation:
The OSPF configuration shown in the exhibit is using the default priority value of 1 for the interface port1. This means that FGT_3 will participate in the DR/BDR election process with the other OSPF routers on the same LAN segment. However, this is not desirable because FGT_3 is a new device that needs to be added to the OSPF network without affecting the existing DR/BDR election. Therefore, to make sure FGT_3 will establish OSPF neighbors without affecting the DR/BDR election, the priority value of the interface port1 should be changed to 0. This will prevent FGT_3 from becoming a DR or BDR and allow it to form OSPF adjacencies with the current DR and BDR. Option B shows the correct configuration that changes the priority value to 0. Option A is incorrect because it does not change the priority value. Option C is incorrect because it changes the network type to point-to-point, which is not suitable for a LAN segment with multiple OSPF routers. Option D is incorrect because it changes the area ID to 0.0.0.1, which does not match the area ID of the other OSPF routers on the same LAN segment. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/administrationguide/ 358640/basic-ospf-example The OSPF configuration shown in the exhibit is using the default priority value of 1 for the interface port1. This means that FGT_3 will participate in the DR/BDR election process with the other OSPF routers on the same LAN segment. However, this is not desirable because FGT_3 is a new device that needs to be added to the OSPF network without affecting the existing DR/BDR election. Therefore, to make sure FGT_3 will establish OSPF neighbors without affecting the DR/BDR election, the priority value of the interface port1 should be changed to 0. This will prevent FGT_3 from becoming a DR or BDR and allow it to form OSPF adjacencies with the current DR and BDR. Option B shows the correct configuration that changes the priority value to 0. Option A is incorrect because it does not change the priority value. Option C is incorrect because it changes the network type to point-to-point, which is not suitable for a LAN segment with multiple OSPF routers. Option D is incorrect because it changes the area ID to 0.0.0.1, which does not match the area ID of the other OSPF routers on the same LAN segment.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/administrationguide/ 358640/basic-ospf-example
Question 5
QUESTION A retail customer with a FortiADC HA cluster load balancing five webservers in L7 Full NAT mode is receiving reports of users not able to access their website during a sale event. But for clients that were able to connect, the website works fine.
CPU usage on the FortiADC and the web servers is low, application and database servers are still able to handle more traffic, and the bandwidth utilization is under 30%.
Which two options can resolve this situation? (Choose two.)
- Change the persistence rule to LB_PERSIS_SSL_SESSJD.
- Add more web servers to the real server poof
- Disable SSL between the FortiADC and the web servers
- Add a connection-pool to the FortiADC virtual server
Correct answer: AD
Explanation:
The FortiADC HA cluster is a load balancing solution that distributes traffic among multiple web servers in L7 Full NAT mode. L7 Full NAT mode means that FortiADC terminates both client and server SSL connections and performs full NAT for both source and destination IP addresses and ports. One possible reason for users not being able to access the website during a sale event is that the persistence rule is not configured properly. Persistence rule is a feature that ensures that subsequent requests from the same client are sent to the same web server, which is important for maintaining session continuity and avoiding errors or data loss. The default persistence rule for L7 Full NAT mode is LB_PERSIS_SRC_IP, which uses the source IP address of the client as the persistence key. However, this rule may not work well if there are many clients behind a proxy or NAT device that share the same source IP address, or if there are clients that change their source IP address frequently due to roaming or switching networks. Therefore, to resolve this situation, one option is to change the persistence rule to LB_PERSIS_SSL_SESSJD, which uses the SSL session ID of the client as the persistence key. This rule can provide more accurate and reliable persistence for SSL connections than LB_PERSIS_SRC_IP. Another possible reason for users not being able to access the website during a sale event is that there are too many TCP connections being established and terminated between FortiADC and the web servers, which consumes CPU resources and causes performance degradation. Therefore, to resolve this situation, another option is to add a connection-pool to the FortiADC virtual server. Connection-pool is a feature that allows FortiADC to reuse existing TCP connections between FortiADC and the web servers, instead of creating new ones for each request. This can reduce CPU overhead, improve response time, and increase throughput. Reference:https://docs.fortinet.com/document/fortiadc/6.4.0/administration-guide/19662/load-balancingmethods-and-persistencehttps://docs.fortinet.com/document/fortiadc/6.4.0/administrationguide/ 19662/connection-pool The FortiADC HA cluster is a load balancing solution that distributes traffic among multiple web servers in L7 Full NAT mode. L7 Full NAT mode means that FortiADC terminates both client and server SSL connections and performs full NAT for both source and destination IP addresses and ports.
One possible reason for users not being able to access the website during a sale event is that the persistence rule is not configured properly. Persistence rule is a feature that ensures that subsequent requests from the same client are sent to the same web server, which is important for maintaining session continuity and avoiding errors or data loss. The default persistence rule for L7 Full NAT mode is LB_PERSIS_SRC_IP, which uses the source IP address of the client as the persistence key. However, this rule may not work well if there are many clients behind a proxy or NAT device that share the same source IP address, or if there are clients that change their source IP address frequently due to roaming or switching networks. Therefore, to resolve this situation, one option is to change the persistence rule to LB_PERSIS_SSL_SESSJD, which uses the SSL session ID of the client as the persistence key. This rule can provide more accurate and reliable persistence for SSL connections than LB_PERSIS_SRC_IP. Another possible reason for users not being able to access the website during a sale event is that there are too many TCP connections being established and terminated between FortiADC and the web servers, which consumes CPU resources and causes performance degradation. Therefore, to resolve this situation, another option is to add a connection-pool to the FortiADC virtual server. Connection-pool is a feature that allows FortiADC to reuse existing TCP connections between FortiADC and the web servers, instead of creating new ones for each request.
This can reduce CPU overhead, improve response time, and increase throughput.
Reference:
https://docs.fortinet.com/document/fortiadc/6.4.0/administration-guide/19662/load-balancingmethods-and-persistence
https://docs.fortinet.com/document/fortiadc/6.4.0/administrationguide/ 19662/connection-pool
Question 6
Refer to the CLI output:
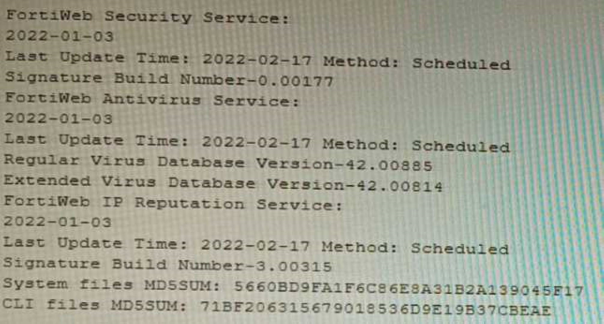
Given the information shown in the output, which two statements are correct? (Choose two.)
- Geographical IP policies are enabled and evaluated after local techniques.
- Attackers can be blocked before they target the servers behind the FortiWeb.
- The IP Reputation feature has been manually updated
- An IP address that was previously used by an attacker will always be blocked
- Reputation from blacklisted IP addresses from DHCP or PPPoE pools can be restored
Correct answer: BE
Explanation:
The CLI output shown in the exhibit indicates that FortiWeb has enabled IP Reputation feature with local techniques enabled and geographical IP policies enabled after local techniques (set geoippolicy-order after-local). IP Reputation feature is a feature that allows FortiWeb to block or allow traffic based on the reputation score of IP addresses, which reflects their past malicious activities or behaviors. Local techniques are methods that FortiWeb uses to dynamically update its own blacklist based on its own detection of attacks or violations from IP addresses (such as signature matches, rate limiting, etc.). Geographical IP policies are rules that FortiWeb uses to block or allow traffic based on the geographical location of IP addresses (such as country, region, city, etc.). Therefore, based on the output, one correct statement is that attackers can be blocked before they target the servers behind the FortiWeb. This is because FortiWeb can use IP Reputation feature to block traffic from IP addresses that have a low reputation score or belong to a blacklisted location, which prevents them from reaching the servers and launching attacks. Another correct statement is that reputation from blacklisted IP addresses from DHCP or PPPoE pools can be restored. This is because FortiWeb can use local techniques to remove IP addresses from its own blacklist if they stop sending malicious traffic for a certain period of time (set local-techniques-expire-time), which allows them to regain their reputation and access the servers. This is useful for IP addresses that are dynamically assigned by DHCP or PPPoE and may change frequently. Reference:https://docs.fortinet.com/document/fortiweb/6.4.0/administration-guide/19662/ip-reputationhttps://docs.fortinet.com/document/fortiweb/6.4.0/administration-guide/19662/geographical-ippolicies The CLI output shown in the exhibit indicates that FortiWeb has enabled IP Reputation feature with local techniques enabled and geographical IP policies enabled after local techniques (set geoippolicy-order after-local). IP Reputation feature is a feature that allows FortiWeb to block or allow traffic based on the reputation score of IP addresses, which reflects their past malicious activities or behaviors. Local techniques are methods that FortiWeb uses to dynamically update its own blacklist based on its own detection of attacks or violations from IP addresses (such as signature matches, rate limiting, etc.). Geographical IP policies are rules that FortiWeb uses to block or allow traffic based on the geographical location of IP addresses (such as country, region, city, etc.). Therefore, based on the output, one correct statement is that attackers can be blocked before they target the servers behind the FortiWeb. This is because FortiWeb can use IP Reputation feature to block traffic from IP addresses that have a low reputation score or belong to a blacklisted location, which prevents them from reaching the servers and launching attacks. Another correct statement is that reputation from blacklisted IP addresses from DHCP or PPPoE pools can be restored. This is because FortiWeb can use local techniques to remove IP addresses from its own blacklist if they stop sending malicious traffic for a certain period of time (set local-techniques-expire-time), which allows them to regain their reputation and access the servers. This is useful for IP addresses that are dynamically assigned by DHCP or PPPoE and may change frequently.
Reference:
https://docs.fortinet.com/document/fortiweb/6.4.0/administration-guide/19662/ip-reputation
https://docs.fortinet.com/document/fortiweb/6.4.0/administration-guide/19662/geographical-ippolicies
Question 7
Refer to the exhibit.
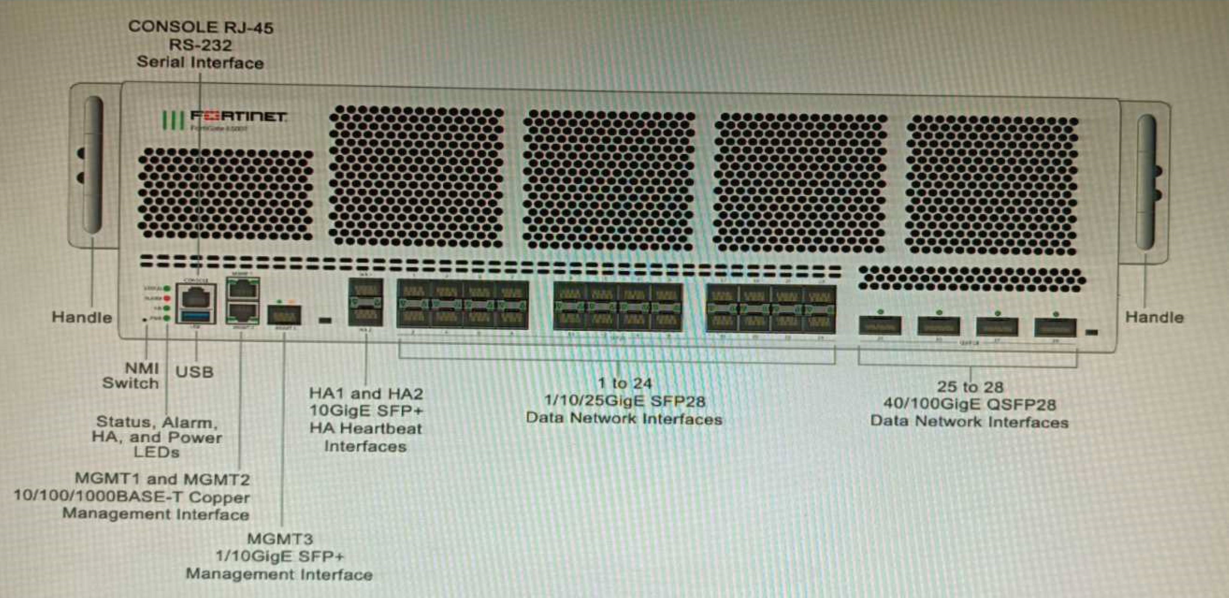
You are deploying a FortiGate 6000F. The device should be directly connected to a switch. In the future, a new hardware module providing higher speed will be installed in the switch, and the connection to the FortiGate must be moved to this higher-speed port.
You must ensure that the initial FortiGate interface connected to the switch does not affect any other port when the new module is installed and the new port speed is defined.
How should the initial connection be made?
- Connect the switch on any interface between ports 21 to 24
- Connect the switch on any interface between ports 25 to 28
- Connect the switch on any interface between ports 1 to 4
- Connect the switch on any interface between ports 5 to 8.
Correct answer: A
Explanation:
The FortiGate 6000F is a high-performance firewall appliance that has 28 network interfaces with different speeds and types. The device should be directly connected to a switch that will have a new hardware module providing higher speed in the future. The connection to the FortiGate must be moved to this higher-speed port without affecting any other port. Therefore, the initial connection should be made on any interface between ports 21 to 24, which are 10G SFP+ interfaces. These interfaces are independent from each other and do not share bandwidth with any other interface. This means that moving the connection to a higher-speed port in the future will not affect any other port on the FortiGate. Option A shows the correct answer. Option B is incorrect because ports 25 to 28 are 40G QSFP+ interfaces, which share bandwidth with ports 21 to 24. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports. Option C is incorrect because ports 1 to 4 are 100G QSFP28 interfaces, which share bandwidth with ports 5 to 8 and ports 9 to 12. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports. Option D is incorrect because ports 5 to 8 are 25G SFP28 interfaces, which share bandwidth with ports 1 to 4 and ports 9 to 12. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/hardware-acceleration-guide/19662/fortigate-6000f The FortiGate 6000F is a high-performance firewall appliance that has 28 network interfaces with different speeds and types. The device should be directly connected to a switch that will have a new hardware module providing higher speed in the future. The connection to the FortiGate must be moved to this higher-speed port without affecting any other port. Therefore, the initial connection should be made on any interface between ports 21 to 24, which are 10G SFP+ interfaces. These interfaces are independent from each other and do not share bandwidth with any other interface.
This means that moving the connection to a higher-speed port in the future will not affect any other port on the FortiGate. Option A shows the correct answer. Option B is incorrect because ports 25 to 28 are 40G QSFP+ interfaces, which share bandwidth with ports 21 to 24. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports. Option C is incorrect because ports 1 to 4 are 100G QSFP28 interfaces, which share bandwidth with ports 5 to 8 and ports 9 to 12. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports. Option D is incorrect because ports 5 to 8 are 25G SFP28 interfaces, which share bandwidth with ports 1 to 4 and ports 9 to 12. Moving the connection to a higher-speed port in the future will affect the bandwidth of these ports.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/hardware-acceleration-guide/19662/fortigate-6000f
Question 8
Which feature must you enable on the BGP neighbors to accomplish this goal?
- Graceful-restart
- Deterministic-med
- Synchronization
- Soft-reconfiguration
Correct answer: A
Explanation:
Graceful-restart is a feature that allows BGP neighbors to maintain their routing information during a BGP restart or failover event, without disrupting traffic forwarding or causing route flaps. Gracefulrestart works by allowing a BGP speaker (the restarting router) to notify its neighbors (the helper routers) that it is about to restart or failover, and request them to preserve their routing information and forwarding state for a certain period of time (the restart time). The helper routers then mark the routes learned from the restarting router as stale, but keep them in their routing table and continue forwarding traffic based on them until they receive an end-of-RIB marker from the restarting router or until the restart time expires. This way, graceful-restart can minimize traffic disruption and routing instability during a BGP restart or failover event. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/cookbook/19662/bgp-graceful-restart Graceful-restart is a feature that allows BGP neighbors to maintain their routing information during a BGP restart or failover event, without disrupting traffic forwarding or causing route flaps. Gracefulrestart works by allowing a BGP speaker (the restarting router) to notify its neighbors (the helper routers) that it is about to restart or failover, and request them to preserve their routing information and forwarding state for a certain period of time (the restart time). The helper routers then mark the routes learned from the restarting router as stale, but keep them in their routing table and continue forwarding traffic based on them until they receive an end-of-RIB marker from the restarting router or until the restart time expires. This way, graceful-restart can minimize traffic disruption and routing instability during a BGP restart or failover event.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/cookbook/19662/bgp-graceful-restart
Question 9
Refer to the exhibit, which shows a Branch1 configuration and routing table.

In the SD-WAN implicit rule, you do not want the traffic load balance for the overlay interface when all members are available.
In this scenario, which configuration change will meet this requirement?
- Change the load-balance-mode to source-ip-based.
- Create a new static route with the internet sdwan-zone only
- Configure the cost in each overlay member to 10.
- Configure the priority in each overlay member to 10.
Correct answer: C
Explanation:
The SD-WAN implicit rule is a default rule that applies to all traffic that does not match any explicit SD-WAN rule. The SD-WAN implicit rule uses the best quality strategy, which selects the SD-WAN member with the best measured quality based on the performance SLA metrics. This means that the traffic load balance for the overlay interface will depend on the quality of each overlay member, which may vary over time. However, if the requirement is to minimize the overhead on the device for WAN traffic and avoid load balancing for the overlay interface when all members are available, one option is to configure the cost in each overlay member to 10. The cost is a parameter that can be used to influence the selection of an SD-WAN member by adding a penalty value to its quality score. By configuring the same cost value for all overlay members, the quality score of each member will be reduced by the same amount, which will make them less preferable than the underlay members. This way, the SD-WAN implicit rule will select the underlay members first, unless they are unavailable or out of SLA, and only use the overlay members as a backup option. Reference:https://docs.fortinet.com/document/fortigate/7.0.0/sd-wan/19662/sd-wan-rules The SD-WAN implicit rule is a default rule that applies to all traffic that does not match any explicit SD-WAN rule. The SD-WAN implicit rule uses the best quality strategy, which selects the SD-WAN member with the best measured quality based on the performance SLA metrics. This means that the traffic load balance for the overlay interface will depend on the quality of each overlay member, which may vary over time.
However, if the requirement is to minimize the overhead on the device for WAN traffic and avoid load balancing for the overlay interface when all members are available, one option is to configure the cost in each overlay member to 10. The cost is a parameter that can be used to influence the selection of an SD-WAN member by adding a penalty value to its quality score.
By configuring the same cost value for all overlay members, the quality score of each member will be reduced by the same amount, which will make them less preferable than the underlay members.
This way, the SD-WAN implicit rule will select the underlay members first, unless they are unavailable or out of SLA, and only use the overlay members as a backup option.
Reference:
https://docs.fortinet.com/document/fortigate/7.0.0/sd-wan/19662/sd-wan-rules
Question 10
Refer to the exhibits.

An administrator has configured a FortiGate and Forti Authenticator for two-factor authentication with FortiToken push notifications for their SSL VPN login. Upon initial review of the setup, the administrator has discovered that the customers can manually type in their two-factor code and authenticate but push notifications do not work Based on the information given in the exhibits, what must be done to fix this?
- On FG-1 port1, the ftm access protocol must be enabled.
- FAC-1 must have an internet routable IP address for push notifications.
- On FG-1 CLI, the ftm-push server setting must point to 100.64.141.
- On FAC-1, the FortiToken public IP setting must point to 100.64.1 41
Correct answer: C
Explanation:
The FortiGate and Forti Authenticator configuration shown in the exhibits is using two-factor authentication with FortiToken push notifications for SSL VPN login. FortiToken push notifications are a feature that allows users to receive a notification on their mobile devices when they attempt to log in to a FortiGate or FortiAuthenticator service, and approve or deny the login request with a single tap. However, push notifications do not work in this scenario, even though users can manually type in their two-factor code and authenticate. One possible reason for this issue is that the FortiGate does not know how to reach the FortiAuthenticator server for push notifications. Therefore, to fix this issue, one option is to configure the ftm-push server setting on FG-1 CLI, which specifies the IP address or FQDN of the FortiAuthenticator server that handles push notifications. In this case, since FAC-1 has an IP address of 100.64.141, the ftm-push server setting on FG-1 CLI must point to 100.64.141 as well. Reference:https://docs.fortinet.com/document/fortiauthenticator/6.4.0/administrationguide/ 19662/fortitoken-mobile-push-notifications The FortiGate and Forti Authenticator configuration shown in the exhibits is using two-factor authentication with FortiToken push notifications for SSL VPN login. FortiToken push notifications are a feature that allows users to receive a notification on their mobile devices when they attempt to log in to a FortiGate or FortiAuthenticator service, and approve or deny the login request with a single tap. However, push notifications do not work in this scenario, even though users can manually type in their two-factor code and authenticate. One possible reason for this issue is that the FortiGate does not know how to reach the FortiAuthenticator server for push notifications. Therefore, to fix this issue, one option is to configure the ftm-push server setting on FG-1 CLI, which specifies the IP address or FQDN of the FortiAuthenticator server that handles push notifications. In this case, since FAC-1 has an IP address of 100.64.141, the ftm-push server setting on FG-1 CLI must point to 100.64.141 as well.
Reference:
https://docs.fortinet.com/document/fortiauthenticator/6.4.0/administrationguide/ 19662/fortitoken-mobile-push-notifications
HOW TO OPEN VCE FILES
Use VCE Exam Simulator to open VCE files

HOW TO OPEN VCEX AND EXAM FILES
Use ProfExam Simulator to open VCEX and EXAM files


ProfExam at a 20% markdown
You have the opportunity to purchase ProfExam at a 20% reduced price
Get Now!